1. pandas loc 사용법
- dataframe.loc[ 행, 칼럼명] 형태로 데이터프레임의 정보를 가져올 수 있다.
loc는 'Location based indexing'을 의미하며, 이를 통해 데이터 프레임에서 특정 행이나 열을 선택할 수 있습니다. 이를 사용하면 인덱스 값 또는 열 이름을 기준으로 특정 데이터를 추출할 수 있습니다.
loc의 사용법은 다음과 같습니다.
DataFrame.loc[index, column]
- index : 선택하려는 행의 인덱스 레이블.
- column : 선택하려는 열의 이름.
실제 예제를 통해 loc를 사용해보겠습니다.
import pandas as pd
# 샘플 데이터 프레임 생성
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 24, 35, 32],
'City': ['New York', 'Paris', 'Berlin', 'London']}
df = pd.DataFrame(data)
print(df)
# loc를 사용한 데이터 선택
print(df.loc[0]) # 첫번째 행 선택
print(df.loc[0, 'Name']) # 첫번째 행의 'Name' 열 선택
print(df.loc[:, 'Age']) # 'Age' 열 전체 선택순서대로, 실행한 결과입니다.

2. pandas iloc 사용법
- dataframe.iloc[ 행위치, 칼럼위치] 형태로 인덱스, 칼럼 숫자 기반으로 데이터를 찾을 수 있다.
iloc는, loc와 다르게 pandas 데이터 프레임에서 인덱스 숫자를 기반으로 데이터를 선택하는 함수입니다. 즉, 행과 열의 위치를 나타내는 숫자를 사용하여 데이터를 선택하게 됩니다.
iloc의 사용법은 다음과 같습니다.
DataFrame.iloc[row_index, column_index]- row_index : 선택하려는 행의 위치를 나타내는 정수.
- column_index : 선택하려는 열의 위치를 나타내는 정수.
아래는 iloc를 이용해 데이터를 가져오는 예제입니다.
print(df)
# iloc를 사용한 데이터 선택
print(df.iloc[2]) # 세번째 행 선택
print(df.iloc[2, 0]) # 세번째 행의 첫번째 열 선택
print(df.iloc[:, 1]) # 두번째 열 전체 선택
앞선 예제의 dataframe에서 위 코드를 실행한 결과입니다.

3. 기타 주의할 점
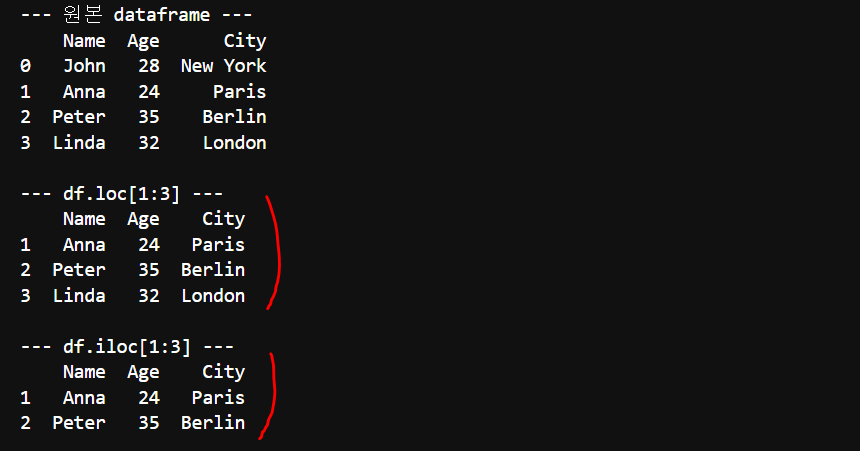
- loc, iloc 슬라이싱( [m:n] )을 사용 시, 끝행의 포함 여부에 주의를 해야 한다. 두 함수의 동작이 다르다.
두 함수 모두 슬라이싱을 지원하며, 이를 통해 행이나 열의 범위를 선택할 수 있습니다. 다만, loc은 끝 값을 포함하는 반면 iloc은 끝 값을 포함하지 않는다는 차이점이 있습니다.
# loc를 사용한 범위 선택
print(df.loc[1:3]) # 두번째 행부터 네번째 행까지 선택
# iloc를 사용한 범위 선택
print(df.iloc[1:3]) # 두번째 행부터 세번째 행까지 선택
실행 결과를 한 번 볼까요? 아래를 보면 원본 데이터프레임에 가져오는 행수가 다름을 확인할 수 있습니다. 혼돈하기 쉬워서 숙지하고 코드를 작성해야 합니다.
이상 loc, iloc 사용법이었습니다.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.iloc.html
'Codyssey > AI선발팀프로젝트' 카테고리의 다른 글
| caffee_map 분석 (2) | 2025.07.24 |
|---|---|
| A* 휴리스틱 알고리즘 + JPS (0) | 2025.07.24 |
| 최단거리 알고리즘 공부 다익스트라 A* (3) | 2025.07.23 |
| 최단거리 그리기 matlib (4) | 2025.07.22 |
| csv 파일을 불러와 내용을 출력하고 분석합니다. (0) | 2025.07.19 |